
3. 数据存储
上面输出的结果是字典格式,可利用 csv 包的 DictWriter 函数将字典格式数据存储到 csv 文件中。
# 数据存储到 csv
def write_to_file3(item):
with open('猫眼 top100.csv', 'a', encoding='utf_8_sig',newline='') as f:
# 'a'为追加模式(添加)
# utf_8_sig 格式导出 csv 不乱码
fieldnames = ['index', 'thumb', 'name', 'star', 'time', 'area', 'score']
w = csv.DictWriter(f,fieldnames = fieldnames)
# w.writeheader()
w.writerow(item)
然后修改一下 main()方法:
def main():
url = 'http://maoyan.com/board/4?offset=0'
html = get_one_page(url)
for item in parse_one_page(html):
# print(item)
write_to_csv(item)
if __name__ == '__main__':
main()
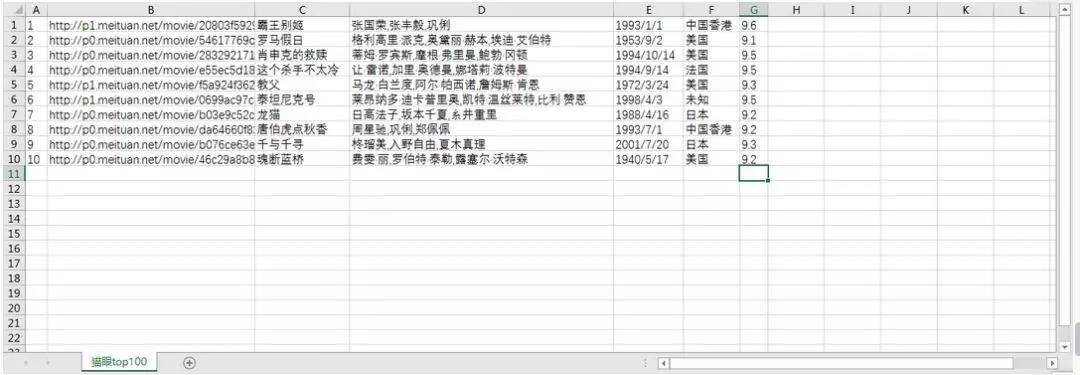
结果如下图: 再把封面的图片下载下来:
def download_thumb(name, url,num):
try:
response = requests.get(url)
with open('封面图/' + name + '.jpg', 'wb') as f:
f.write(response.content)
print('第%s 部电影封面下载完毕' %num)
print('------')
except RequestException as e:
print(e)
pass
# 不能是 w,否则会报错,因为图片是二进制数据所以要用 wb
这样我们就完成了第一页信息爬取和存储。一共有十页信息,下面我们构造一个简单
这样我们就完成了第一页信息爬取和存储。一共有十页信息,下面我们构造一个简单的循环,就可以爬取全部页数信息。
4. 分页爬取
剩下 9 页共 90 部电影的数据可以给网址传入一个 offset 参数,然后遍历 URL 重复执行上面的过程即可,代码修改如下:
def main(offset):
url = 'http://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
write_to_csv(item)
if __name__ == '__main__':
for i in range(10):
main(offset = i*10)
这样我们就爬取了全部电影信息,结果如下:
5. 数据分析
俗话说“文不如表,表不如图”。下面爬取的数据做简单的数据可视化分析。
5.1. 评分最高的十部电影
先来看一看评分最高的十部电影是哪些,代码编写如下:
import pandas as pd
import matplotlib.pyplot as plt
import pylab as pl #用于修改 x 轴坐标
plt.style.use('ggplot') #默认绘图风格很难看,替换为好看的 ggplot 风格
fig = plt.figure(figsize=(8,5)) #设置图片大小
colors1 = '#6D6D6D' #设置图表 title、text 标注的颜色
columns = ['index', 'thumb', 'name', 'star', 'time', 'area', 'score'] #设置表头
df = pd.read_csv('maoyan_top100.csv',encoding = "utf-8",header = None,names =columns,index_col = 'index') #打开表格
# index_col = 'index' 将索引设为 index
df_score = df.sort_values('score',ascending = False) #按得分降序排列
name1 = df_score.name[:10] #x 轴坐标
score1 = df_score.score[:10] #y 轴坐标
plt.bar(range(10),score1,tick_label = name1) #绘制条形图,用 range()能搞保持 x 轴正确顺序
plt.ylim ((9,9.8)) #设置纵坐标轴范围
plt.title('电影评分最高 top10',color = colors1) #标题
plt.xlabel('电影名称') #x 轴标题
plt.ylabel('评分') #y 轴标题
# 为每个条形图添加数值标签
for x,y in enumerate(list(score1)):
plt.text(x,y+0.01,'%s' %round(y,1),ha = 'center',color = colors1)
pl.xticks(rotation=270) #x 轴名称太长发生重叠,旋转为纵向显示
plt.tight_layout() #自动控制空白边缘,以全部显示 x 轴名称
# plt.savefig('电影评分最高 top10.png') #保存图片
plt.show()
结果如下图:

可以看到,排名最高的分别是两部国产片《霸王别姬》和《大话西游》,其他还包括《肖申克的救赎》、《教父》等。
5.2. 各国电影数量对比
来了解一下这 100 部电影都是来自哪些国家,代码编写如下:
area_count = df.groupby(by = 'area').area.count().sort_values(ascending = False)
# 绘图方法 1
area_count.plot.bar(color = '#4652B1') #设置为蓝紫色
pl.xticks(rotation=0) #x 轴名称太长重叠,旋转为纵向
# 绘图方法 2
# plt.bar(range(11),area_count.values,tick_label = area_count.index)
for x,y in enumerate(list(area_count.values)):
plt.text(x,y+0.5,'%s' %round(y,1),ha = 'center',color = colors1)
plt.title('各国/地区电影数量排名',color = colors1)
plt.xlabel('国家/地区')
plt.ylabel('数量(部)')
plt.show()
# plt.savefig('各国(地区)电影数量排名.png')
结果如下图:

可以看到,除去网站自身没有显示国家的电影以外,上榜电影被 10 个国家/地区"承包"了。其中,美国以 30 部电影的绝对优势占据第 1 名,其次是 8 部的日本,7 部的韩国。香港有 5 部,而内地一部都没有。
5.3. 电影大年
这些电影拍摄的年份时间跨度很大,统计一下各年的电影数量,看看是否存在"电影大年"。
# 从日期中提取年份
df['year'] = df['time'].map(lambda x:x.split('/')[0])
# print(df.info())
# print(df.head())
# 统计各年上映的电影数量
grouped_year = df.groupby('year')
grouped_year_amount = grouped_year.year.count()
top_year = grouped_year_amount.sort_values(ascending = False)
# 绘图
top_year.plot(kind = 'bar',color = 'orangered') #颜色设置为橙红色
for x,y in enumerate(list(top_year.values)):
plt.text(x,y+0.1,'%s' %round(y,1),ha = 'center',color = colors1)
plt.title('电影数量年份排名',color = colors1)
plt.xlabel('年份(年)')
plt.ylabel('数量(部)')
plt.tight_layout()
# plt.savefig('电影数量年份排名.png')
plt.show()
结果如下图:

可以看到,100 部电影来自 37 个年份。其中 2011 年上榜电影数量最多,达到 9 部;其次是 2010 年的 7 部。网上盛传的传" 1994 电影史奇迹年" 仅排名第 6,猫眼榜单的权威性有待考量。
另外,上世纪三四十年代也有电影上榜,那会儿还是黑白电影,反映了电影的口碑好坏跟外在技术没有绝对的关系,质量才是王道。
5.4. 电影作品最多的演员
最后,看看前 100 部电影中哪些演员的作品数量最多。
#表中的演员位于同一列,用逗号分割符隔开。需进行分割然后全部提取到 list 中
starlist = []
star_total = df.star
for i in df.star.str.replace(' ','').str.split(','):
starlist.extend(i)
# print(starlist)
# print(len(starlist))
# set 去除重复的演员名
starall = set(starlist)
# print(starall)
# print(len(starall))
starall2 = {}
for i in starall:
if starlist.count(i)>1:
# 筛选出电影数量超过 1 部的演员
starall2[i] = starlist.count(i)
starall2 = sorted(starall2.items(),key = lambda starlist:starlist[1] ,reverse = True)
starall2 = dict(starall2[:10]) #将元组转为字典格式
# 绘图
x_star = list(starall2.keys()) #x 轴坐标
y_star = list(starall2.values()) #y 轴坐标
plt.bar(range(10),y_star,tick_label = x_star)
pl.xticks(rotation = 270)
for x,y in enumerate(y_star):
plt.text(x,y+0.1,'%s' %round(y,1),ha = 'center',color = colors1)
plt.title('演员电影作品数量排名',color = colors1)
plt.xlabel('演员')
plt.ylabel('数量(部)')
plt.tight_layout()
plt.show()
# plt.savefig('演员电影作品数量排名.png')
结果如下图:
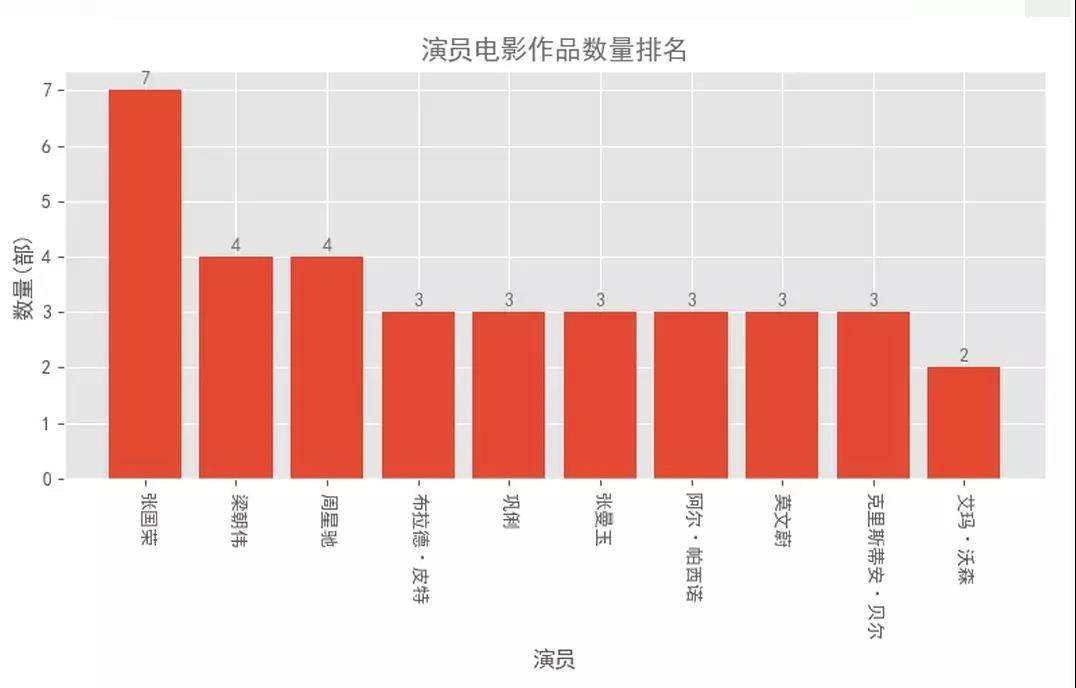
张国荣排在了第一位,觉得意外么?其次是梁朝伟和周星驰,再之后是布拉德·皮特。仔细数一下,前十名影星中,香港影星占了 6 位,这份榜单真是偏爱港星。
对张国荣以七部影片的巨大优势占据第一感到好奇,来看看是哪七部电影。
df['star1'] = df['star'].map(lambda x:x.split(',')[0]) #提取 1 号演员
df['star2'] = df['star'].map(lambda x:x.split(',')[1]) #提取 2 号演员
star_most = df[(df.star1 == '张国荣') | (df.star2 == '张国荣')][['star','name']].reset_index('index')
# |表示两个条件或查询,之后重置索引
print(star_most)
可以看到包括排名第一的《霸王别姬》、第 17 名的《春光乍泄》、第 27 名的《射雕英雄传之东成西就》等。这些电影你都看过么。
index star name
0 1 张国荣,张丰毅,巩俐 霸王别姬
1 17 张国荣,梁朝伟,张震 春光乍泄
2 27 张国荣,梁朝伟,张学友 射雕英雄传之东成西就
3 37 张国荣,梁朝伟,刘嘉玲 东邪西毒
4 70 张国荣,王祖贤,午马 倩女幽魂
5 99 张国荣,张曼玉,刘德华 阿飞正传
6 100 狄龙,张国荣,周润发 英雄本色
以上,我们使用了多种方法爬取并分析了猫眼 TOP 100 电影,初步了解了爬虫的基本技法。
文中完整代码和素材,可以在下方链接中得到:
https://github.com/makcyun/web_scraping_with_python/tree/master/%E7%8C%AB%E7%9C%BC%E7%94%B5%E5%BD%B1top100
想实操Python爬虫以及其他Python入门项目案例,拼客学院《Python5天入门实战营》等你来!该训练营针对Python零基础的同学,旨在通过项目实战的教学方法,每天通过3-4小时的学习,完成至少两项入门级Python项目并入门Python编程。

课程安排
Day 1:
Python入门导论
Python学习路线
Python基础入门
Day 2:
Python数据结构
Python条件判断
Day 3:
Python函数编程
Day 4:
Python游戏开发
Day 5:
Python网络爬虫
选修:
Python人脸识别
本课程限时免费招募
限额200人,人满即关闭报名通道
授课形式:录播形式,10节Python视频课程+每日匹配作业,4周内可无限回看,训练营结束后失效。
社群答疑
开营期间,班主任及助教老师会在班级群提供在线答疑。
奖励机制
结营后学员完成所有作业可获得[结业证书]+奖学金!
免费报名方式
长按识别下方二维码,
回复关键词「 1324 」即可获得报名入口▼

关于拼客学院
▼
拼客学院(PINGINGLAB)是国内领先的新IT职业教育品牌,由院长陈鑫杰创立于2013年,核心团队来自IBM / 百度 / 网易 / 新东方 / 欢聚时代等知名企业。
拼客学院专注为在校大学生与职场新人提供深入一线的IT实战技能,涵盖网络安全、Linux运维、云计算、人工智能、大数据、新兴软件开发等众多高端技术领域,90%以上内容由一线IT名企的技术专家 / 资深工程师 / 项目负责人共同打造。
作为一家新型IT互联网技术大学,拼客学院秉承「以企业需求为根本,以学员口碑为生命线」的初心,坚守「让学员找到好工作,让企业招到好伙伴」的使命,以教学口碑和课程质量驱动发展,超过50%学员口口相传而来,好评率⾼达96%,每位学员可以拿到2.5到3个名企offer,就业率与入职薪酬遥遥领先。截止目前,已累积培养300万+线上与数千名面授学员,遍布国内一线的互联网 / 游戏 / 电商 / 网络安全 / 运营商 / 金融 / 公安 / 政府等各行各业。
拼客学院[100%保offer计划]全栈Python开发工程师,2019年4月开班,冲击年薪20-30万,速抢名额~~~
——END——
技术交流群1:
添加班主任微信 qiuzhiquanquan 或 qqls000
加入微信群
技术交流群2:
添加班主任QQ 1724698994 或 1752856301
加入QQ群(240920680)
文章来源: 拼客学院服务号
- 还没有人评论,欢迎说说您的想法!